“Rich feature Hierarchies for accurate object detection and semantic segmentation”, 즉 , R-CNN은 2014년 CVPR에 발표되었다. 이전과 달리 sliding window를 사용해 각각의 bounding box에 대해 classification을 수행하지 않고 selective search를 이용해 객체가 있을 법한 위치를 추천 받아 classification을 수행하는 방식이다. 이 논문 이후 위치를 추천받는 다양한 Region proposal 기법들이 소개되었다.
Object detection with R-CNN
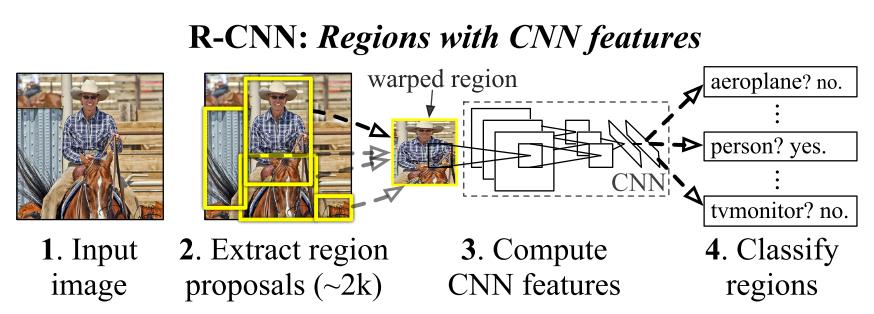
R-CNN은 다음의 세 가지 module로 구성 되어 있다.
- Region Proposal : 이미지내에서 객체가 있을 법한 위치를 추천한다.
- CNN : 이미지의 추천된 영역으로부터 고정된 크기의 feature vector를 추출한다.
- SVM : feature vector로 부터 class를 예측한다.
1.Region Proposal : Selective Search

Selective search는 색상, 명암, 무늬 등 다양한 그룹화 기준을 고려해 초기 그룹으로부터 bottom-up 그룹화를 하는 방식이다. 좌측 상단의 그룹으로부터 우측 상단의 그룹으로 가며 각 하단 이미지들과 같이 bounding 영역을 그려낼 수 있고 본 논문에서는 약 2000개의 bounding 영역들이 region proposal이 된다.
이 알고리즘의 그룹화 과정은 greedy한 알고리즘을 사용한다. 즉, 해당 알고리즘은 trainable한 가중치가 존재하지 않다.
selective search는 분명히 sliding window에 비해 굉장히 빠른 방식이다. 하지만 약 2000개의 영역들을 각각 CNN에 입력으로 넣기 때문에 속도가 여전히 느리다. 이러한 부분은 다른 논문에 의해 점점 개선된다.
2.CNN
CNN 부분은 Alex net의 feature extraction 부분을 사용한다. 따라서 모델 구조는 이전 포스팅으로 대체 하고 어떻게 고정된 크기의 feature를 만드는지에 대해 설명한다.
왜 이런 고민을 할까? 우리는 Selective search에 의해 영역을 추천받았다. 영역은 bounding box의 형태, 즉 4가지의 좌표를 받을 것이다. 이 4가지 좌표를 이용해 우리는 원본 이미지에서 ROI 영역을 설정할 수 있다. 하지만 이 영역들은 서로 크기나 종횡비가 다르다. 이를 CNN의 입력으로 넣으면 서로 다른 크기의 feature vector들이 생겨날 것이다. 그렇다면 ROI 영역을 모두 동일하게 227 x 227 크기로 만들면 되는데 본 논문에서는 다양한 방법으로 실험을 진행했다.

위 사진에서 A에 해당하는 부분이 추전받은 영역이다. 만약 우리가 추천받은 영역이 14 x 28 이라면 이 영역을 감쌀 수 있는 최소 크기의 정사각형은 28 x 28이다. 그렇다면 추천받은 영역이 정중앙에 위치하고 28 x 28의 나머지 부분을 원본 이미지로 채운 후 resize를 진행한 것이 (B), 나머지 부분을 채우지 않은 방식이 (C)이다. 그리고 마지막 (D)는 resize를 바로 적용한 결과이다.
A,B,C,D 각 방식이 위 아래로 분리되어 있는데 위 사진은 padding을 적용하지 않은 이미지이며 아래 사진은 padding을 16으로 설정한 결과이며 이 때가 성능이 가장 좋았다고 한다. padding을 적용했을 때 주변 픽셀이 더 많이 포함된 것을 보면 bounding box에 padding을 적용하는 것 같다.
3.SVM
이제 우리는 고정된 크기의 저차원 vector를 얻었으므로 이를 하나의 Bag-of-visual-word encodings로 볼 수있다. 우리는 이 정보들을 이용해 SVM을 수행하고 겹쳐진 영역에 대해서는 non-mximum suppression을 수행한다.
Training
R-CNN은 classification과 bounding box regression이 동시에 이루어지지 않는다. 따라서 train이 다소 난해하게 진행된다.
Pre-training
가장 먼저 image net과 같은 큰 데이터 셋에서 classification을 pre training 한다. 이 단계에서 CNN의 feature extraction 부분이 이미지에 대한 표현을 학습한다.
Domain-specific fine-tuning
그 다음 1000개의 class(image net의 class 개수)에 대해 예측하던 마지막 fc-layer를 1001개로 변경한다. 이때 추가된 1개의 클래스는 해당 영역이 전경인지 배경인지에 대한 class이다. 만약 해당 영역이 ground truth와 0.5이상의 IOU를 가진다면 전경, 그외에는 배경으로 라벨이 된다. 각 iteration 당 128크기의 배치 사이즈중 32개의 전경(positive example)과 96개의 배경(negative example)을 학습한다. 이때, SGD의 learning rate = 0.001로 설정 되었다.
Object category classifiers
fc를 SVM으로 classifier를 변경했다(실험 결과 softmax보다 더 높은 결과가 나왔다고 한다). 그리고 fine-tuning 때 IOU에 대해 0.5의 임계값을 설정한 반면 SVM에서는 0.3 IOU미만이면 negative, 0.5이상이면 positive로 설정한다.
Bounding box regression
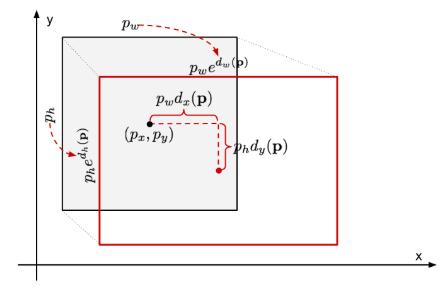
Selective search에 의해 추천된 bounding 영역은 말그대로 추천이기 때문에 정확하지 않다. 따라서 이를 조정하기위해 Bounding box를 예측하는 부분을 추가한다. 훈련된 CNN으로부터 고정된 크기의 벡터를 입력으로 받아 bounding box의 4가지 정보를 예측하는 fc-layer를 train한다. Ground truth의 좌표를 \(G\), Selective search가 추천한 영역의 좌표를 P라고 한다면 P가 G가 되기 위한 조정을 학습한다. 이를 식으로 나타내면 아래와 같다.
\[\hat{G}_{x} = P_{w}d_{x}(P)+P_{x} \\ \hat{G}_{y} = P_{h}d_{y}(P)+P_{y} \\ \hat{G}_{w} = P_{w}exp(d_{w}(P)) \\ \hat{G}_{h} = P_{h}exp(d_{h}(P))\]여기서 \(d(P)_{*}\)는 fc-layer의 output이며 우리가 학습할 대상이다. 추천된 영역을 CNN의 입력으로 넣었을 때 5번째 pooling layer의 output(고정된 크기의 벡터)을 \(\phi_{5}(P)\)로, 우리가 학습해야할 weight를 \(\mathbf{w}_{*}\)로 표현하면 \(d(P)_{*}\)는 \(\hat{\mathbf{w}}_{*}^{T} \phi_{5}(P)\)로 나타내면 bounding box regression에 대한 목적함수는 아래와 같다.
\[argmin_{w_{*}} \sum^{N}_{i}(t_{*}^{i} - \hat{\mathbf{w}}_{*}^{T}\phi_{5}(P^{i}))^{2} + \lambda \begin{Vmatrix}\hat{\mathbf{w}}_{*}\end{Vmatrix}^{2}\]오른쪽 \(\lambda\) 항은 regularization 항이다.
마지막으로 학습 순서를 다시 정리하면 다음과 같다.참고
- ImageNet의 Classification 데이터로 ConvNet을 pre-train 시킨다.
- pre-trained 모델을 기반으로, object detection 데이터로 ConvNet을 fine-tuning한다.
- object detection 데이터의 region proposal들에 대해 고정된 크기의 feature 벡터를 추출해 저장한다.
- 추출된 feature 벡터를 기반으로 SVM을 학습한다.
- 추출된 벡터를 기반으로 bounding-box regressor를 학습한다.
Result
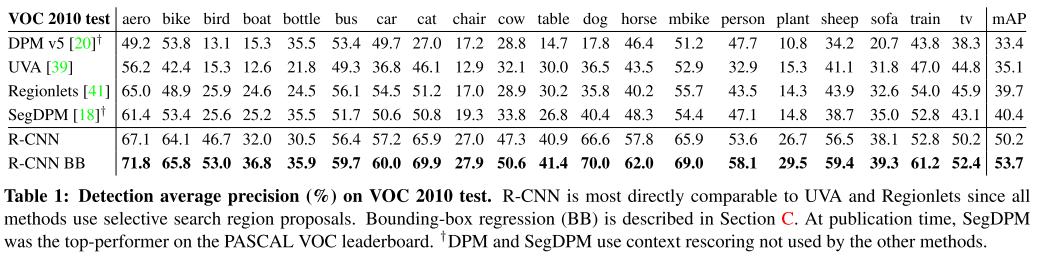
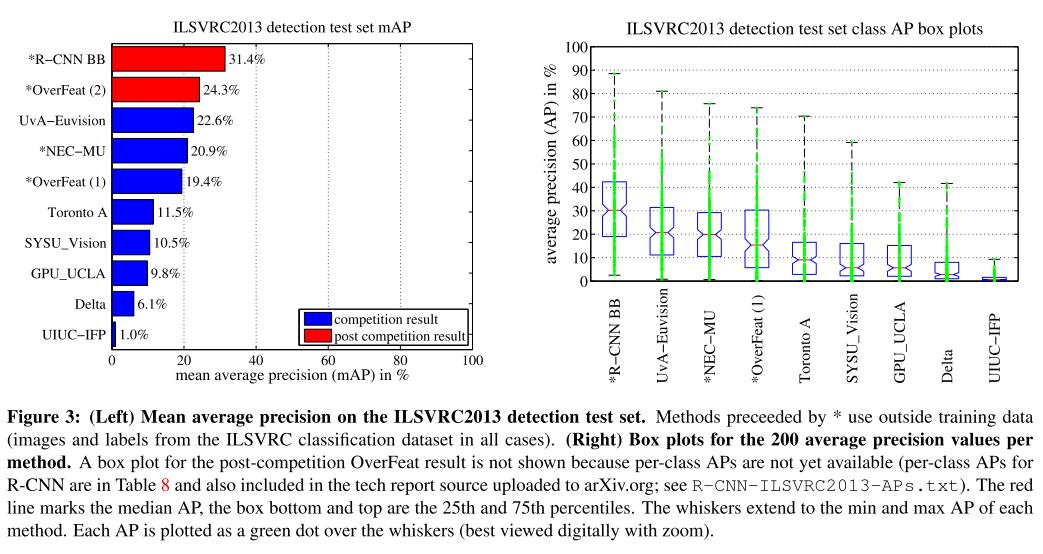
결과에서는 이전에 제안되었던 모델보다 월등히 높은 정확도를 보여준다. 물론 현재에는 사용되지 않지만 이후 여러 Region proposal 모델들이 등장하는 계기가 되었다.
Reference
[1] R. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. In CVPR, 2014.
Comments